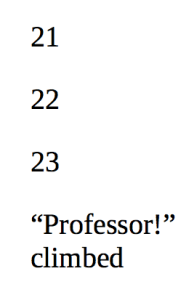
A couple of weeks ago, after this post about inserting the blurb at the front of an ebook, a reader emailed me asking about cleaning up PDF files when converting to ePub. Often there will be stray letters or numbers or headers that affect the output of an ebook. There are some tips and tricks in Calibre’s PDF conversion engine that can be used to produce very clean and readable PDFs. I’m going to address three of the most common problems when converting a PDF to ePub and what you can do to address those problems.
Some PDFs have line numbers that are on a hidden layer. When you read the PDF you can’t see them, but when you convert to ePub or Mobi they appear within the text and render the converted book unreadable. There’s a very easy fix to this.
Under “Convert books” select “Search and Replace”:
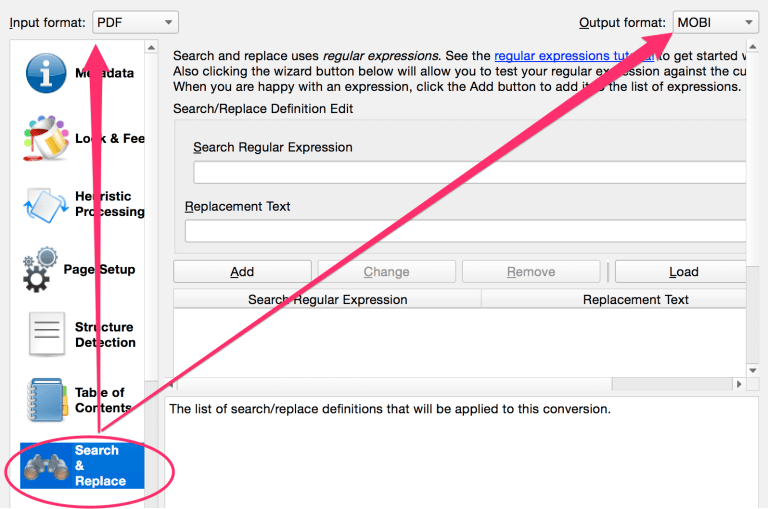

The first thing you want to do is click on the wizard button. This will bring up a dialogue box that shows what the PDF looks like before conversion. There’s a number followed by
, then a line break. You don’t want any of that.

To remove the numbers and the
which is CSS for a line break, your code would be:

As you scroll down, sometimes you will see these line numbers that start with S or N.

or sometimes the line numbers will end with S and N.

To construct the search text, you would simply add the S or N before or after the number.
Or, if you’re really savvy, you’ll use the \w code. \w removes a single word character.
The | is called a pipe and it is used to separate sets of regular expressions. I’m sure there is a more sophisticated query but it works for me.

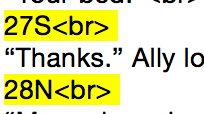
Now when you scroll down, those pesky stray line numbers should be highlighted. Press okay and you’ll be sent back to the Search and Replace window. The replace term is left completely blank. Press “Add” or your conversion won’t include the search and replace you just constructed.

Your search expression appears in the left with the replacement text (blank in this case) on the left.
If that’s all you need to exclude, then press “OK” and the conversion will begin. Often, however, there will be headers that need to be removed.
In the following book there was an alternating header with author name and title. Remember, the number and text will often change from page to page.
Anne Calhoun
Liberating Lacey
and a footer with the page numbers:
Basically I copy any text that needs to be removed and then replace the number with \d+. My reg expression is as follows.
)(Anne Calhoun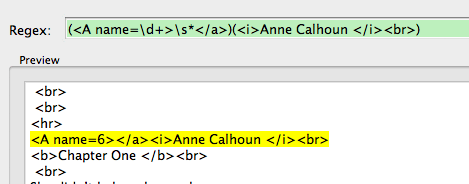
Highlight the text to be removed and then replace the numbers with \d+. You could add a \s+ between “Lacey” or “Calhoun” and the just to be on the safe side: Liberating Lacey\s*
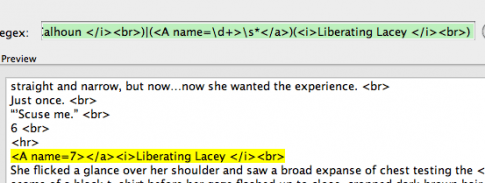
The \s+ removes excess white spaces.
Calibre has a feature called Heuristic Processing which scans the ebook and tries to search for common errors and fixes them. I use this function primarily to unwrap lines. In this example, you can see the paragraph is broken up by these weird line wraps and reading a book in this format would be impossible.

The default for Heuristic Processing is that it is disabled. So check the box and the options will become available. The default for the line unwrap is .40 and frankly that setting usually never works for me.
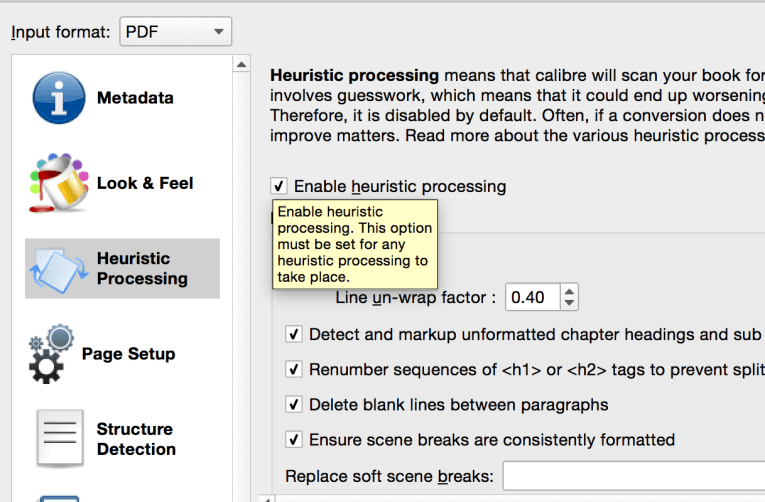
You often will have to play around with this and reformat at different settings. In this example, I had to reduce the line unwrap factor to 0.5 to get the paragraphs to be readable.

A soft scene break is when there is an extra space between different scenes in a book rather than the use of a wingding (. ) or some small graphic such as hashmarks (###) or bullets (•••). You can replace the soft scene breaks with your own text or graphic to further customize the look and feel of your ebooks.
Hope this helps!
We have a wealth of development experience and are committed to providing the best products for our customers.