Gustavo du Mortier is a functional and data analyst at MasterSoft, an Argentinean software company specializing in ERP and healthcare solutions. He’s written many books and articles on different aspects of programming and databases. In his spare time, he plays guitar and helps his two sons build and enhance their gaming computers.
Assigning names to objects in your database is not a trivial task. This list of best practices for naming conventions in data modeling will help you do it the right way.
The task of designing a database schema is similar to that of creating the plans of a building. Both are carried out by making drawings in an abstract, theoretical framework. But they must be done with the understanding that these drawings will later become robust structures that support large constructions – in one case, constructions made of solid materials; in the other, constructions made of data.
(If you’re not familiar with the basics of data modeling and database design, read what a database schema is to clear up any doubts before you continue.)
Like the plans of a building, the design of a database schema cannot readily be changed when construction is underway. In our case, this is when the database is already up and running and its tables are populated with data.
Even the names of objects cannot be changed without the risk of breaking the applications accessing the database. This highlights the importance of establishing very clear database schema naming conventions as the first step in schema design. Then you can go on following the steps on how to draw a database schema from scratch.
Let’s look at some best practices for database naming conventions that could help you avoid name-related problems during the database life cycle.
Before you start any actual modeling – or come up with any naming conventions, for that matter – you should lay the foundations for your database naming convention.
The first best practice for naming conventions in data modeling is to write down all the criteria defining the adopted naming convention. So that it is always visible and at hand, it should be included as a text annotation together with the entity-relationship diagram (ERD). If you use a database design tool like Vertabelo, your naming conventions in database modeling can be documented in virtual sticky notes that will always be attached to your ERDs. This and other database modeling tips can save you time and effort when doing data modeling work.
I’ve had to work with many databases where the names of objects were intentionally obfuscated or reduced to short, fixed-length strings that were impossible to understand without resorting to a data dictionary. In some cases, this was because of a not-very-logical confidentiality requirement; in other cases, it was because whoever designed the schema thought that encoding the names might be useful for some purpose.
In my experience, adopting a database schema naming convention that forces developers and designers to encode object names, or to use names with no meaning at all, is a complication without any benefit.
So, the first best naming convention practice is to use meaningful names. Avoid abstract, cryptic, or coded combinations of words. To see other bad examples of naming conventions in data modeling, check out the 11 worst database naming conventions I’ve seen in real life.
Also, choosing one of the top 7 database schema design tools could be considered one of the best practices for database naming conventions. There is no point in using common drawing tools when there are intelligent tools that pave the way to create flawless diagrams that turn into robust databases.
In software systems that are used and developed in a single country, there’s probably no need to specify the language. But if a system involves designers or developers of different nationalities (which is becoming increasingly common), language choice is not trivial. In such situations, the language used to name schema objects must be clearly specified in the naming convention and must be respected. This way, there will be no chances of finding names in different languages.
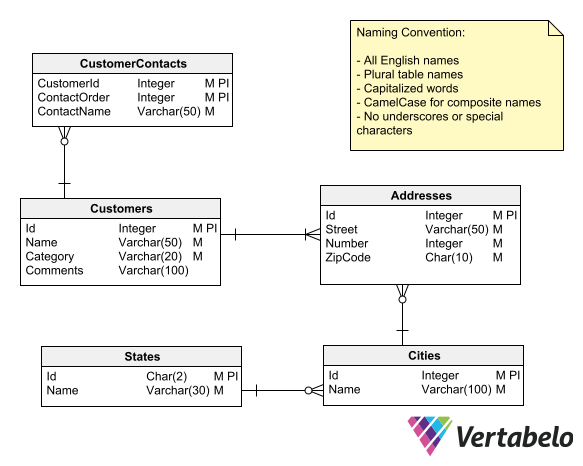
Database schema naming conventions must be explicit in ER diagrams.
Database tables represent real-world entities, so it is appropriate to use nouns when choosing their names. When considering database table naming conventions, you must make a decision that seems trivial but is actually crucial: use plural or singular nouns for the names. (In the case of database column naming conventions, this problem does not arise, as column names are always singular.)
Some say that the singular should be used because tables represent a single entity, not a collection of things. For example: Client , Item , Order , Invoice , etc. Others prefer to use the plural, considering that the table is a container for a collection of things. So, with the same criteria as they would label a box for storing toys, they give the tables plural names: Customers , Items , Orders , Invoices .
Personally, I’m on Team Plural. I find it easier to imagine the table as a labeled box containing many instances of what the label says than to imagine it as an individual entity. But it's just a matter of preference. What is important – as with all aspects of database schema naming conventions – is to make a choice before you start designing and stick with it throughout the life cycle of the database.
While it is possible to use spaces and any printable character to name tables and other database objects, this practice is strongly discouraged. The use of spaces and special characters requires that object names be enclosed in delimiters so that they do not invalidate SQL statements.
For example, if you have a table in your schema called Used Cars (with a space between Used and Cars ), you’d have to write the table name between delimiters in any query that uses it. For example:
SELECT * FROM `Used Cars`
SELECT * FROM [Used Cars]
This is not only a nuisance for anyone writing SQL code, it is also an invitation to make mistakes. An easy mistake (but one that’s difficult to detect) would be unintentionally typing two spaces instead of one.
The best practice is to avoid spaces and special characters when naming database objects, with the exception of the underscore. The latter can be used (as explained below) to separate words in compound names.
SQL is case-insensitive, so the case-sensitivity of object names is irrelevant when writing queries or issuing SQL commands to your database. However, a good practice for database schema naming is to clearly define a case-sensitive criteria for object names. The criteria adopted will affect the readability of the schema, its neatness, and the interpretation of its elements.
For example, you can use names with all capital letters for tables and upper/lower case for columns. This will make it easier to identify objects in database diagrams as well as in SQL statements and other database tools. If you are ever faced with the task of reviewing an execution log with thousands of SQL commands, you will be thankful that you have adopted a case-sensitive approach.
The ideal name for any database object should strike the optimal balance between synthesis and self-explanation. Ideally, each name should contain an explanation of what it represents in the real world and also be able to be synthesized in one word. This is easy to achieve in some cases, particularly when you create a conceptual schema with tables that contain information on tangible elements: Users , Employees , Roles , Payrolls , etc.
But as you get a bit more detailed in your diagrams, you will come across elements that cannot be self-explanatory with a single word. You will then have to define names for objects that represent, for example, roles per user, payroll items, ID numbers, joining dates, and many others.
Another good schema naming practice is to adopt clear criteria for the use of compound names. Otherwise, each designer or programmer will use their own criteria – and your schema will quickly become full of random names.
There are two popular naming options for using compound names. You can either use camel case (e.g. PayrollItems or DateOfBirth ) or you can separate the words with an underscore, (e.g. PAYROLL_ITEMS or DATE_OF_BIRTH ).
Using underscore as a word separator in compound names is the way to go for capitalized names; it ensures the names can be easily read at a glance.
Using abbreviations for object names is inadvisable, but so is using names that are too long. Ideally, a middle ground should be found. For example, I recommend only abbreviating object names if the name exceeds 20 characters.
If you make heavy use of abbreviations because many objects in your schema have long names, the list of abbreviations to be used should be explicit for all users of your schema. In addition, this list should be part of the naming convention of your schema. You can add a sticky note to your diagrams where you explicitly detail all abbreviations used along with their extended meaning.
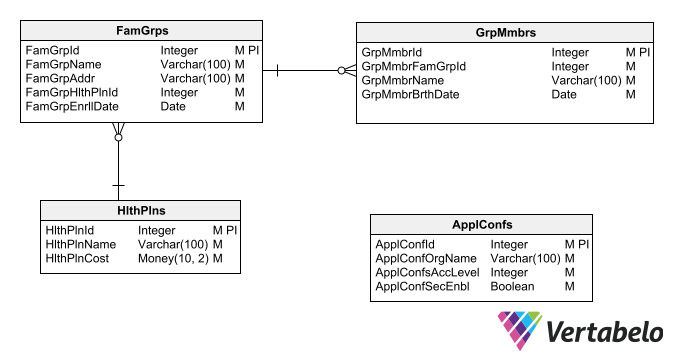
Abbreviations and prefixes should be avoided; they only cause confusion to everyone that needs to work with the database.
Some people use prefixes or suffixes to denote an element’s type so that it can be easily identified without referencing the schema description or the database metadata. For example, they add the prefix T_ to all tables and V_ to all views. Or they add a suffix that denotes the data type of each column.
Using suffixes or prefixes may result in two objects of different types with similar names. For example, you could easily have a table named T_CUSTOMERS and a view named V_CUSTOMERS . Whoever has to write a query may not know which of the two should be used and what the difference is between them.
Remember that a view name should indicate its purpose. It would be more helpful if the view name were, for example, NEW_CUSTOMERS , indicating that it is a subset of the CUSTOMERS table.
Using a suffix indicating the data type of each column does not add useful information. The exception is when you need to use a counter-intuitive data type for a column. For example, if you need a column to store a date in integer format, then you could use the int suffix and name the column something like Date_int .
Another common (but discouraged!) practice is to prefix each column name with an abbreviation of the table name. This adds unnecessary redundancy and makes queries difficult to read and write.
A prefix denoting the type of object is considered good practice when naming table- or column-dependent objects (e.g. indexes, triggers, or constraints). Such objects are not usually represented in database diagrams, instead being mentioned in schema metadata queries, in logs or execution plans, or in error messages thrown by the database engine. Some commonly used prefixes are:
The suggested way to use these prefixes is to concatenate them with the table name and an additional element denoting the function the constraint performs. In a foreign key constraint, we might indicate the table at the other end of the constraint; in an index, we might indicate the column names that compose this index. A foreign key constraint between the Customers table and the Orders table could be named FK_Customers_Orders .
This way of naming dependent objects makes it easier to relate the object to the table(s) on which it depends. This is important when it is mentioned in an execution log or error message.
Since you don’t usually have to write the names of dependent objects (like foreign keys or indexes) in SQL statements, it’s not really important if they are long or do not meet the same naming criteria as objects like tables, fields, or views.
Another commonly accepted use for prefixes is to quickly distinguish sets of objects that belong to a functional or logical area of the schema. For example, in a data warehouse schema prefixes let us distinguish dimension tables from fact tables. They can also distinguish tables with “cold data” from tables with “hot data”, if this kind of distinction is a top priority in your schema.
In a schema that is used by different applications, prefixes can help to easily identify the tables that are used by each application. For example, you can establish that tables starting with INV belong to an invoicing app and those starting with PAY belong to a payroll app.
As I recommended above for abbreviations, these prefixes need to be made explicit in the database diagram, either through sticky notes or some other form of documentation. This form of grouping by prefix will make it easier to manage object permissions according to the application that uses them.
It is quite common to create views in a database schema to facilitate the writing of queries by solving common filtering criteria. In a schema that stores membership information, for example, you could create a view of approved memberships. This would save database developers the task of finding out what conditions a membership must meet to be approved.
For the above reason, it is common for view names to consist of the table name plus a qualifier designating the purpose of that view. Since views named in this way often have compound names, you should use the criteria you’ve adopted for compound names. In the example above, the view might be called ApprovedMemberships or APPROVED_MEMBERSHIPS , depending on the criteria chosen for compound names. In turn, you could create a view of memberships pending approval called PendingMemberships or PENDING_MEMBERSHIPS .
Since views are used as if they were tables, it is good practice that their names follow the same naming convention as table names – e.g. if you use all uppercase for table names, you should also use all uppercase for view names.
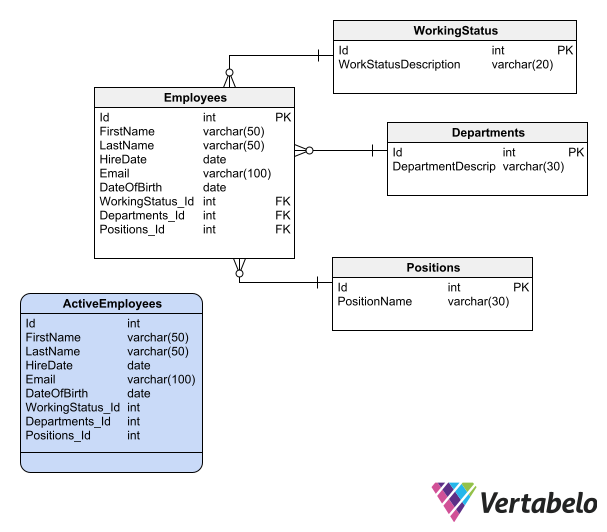
It is a good practice to name views after their “mother” table (when there is one), adding a qualifier that designates the purpose of that view.
It’s important to make views known. Anyone who uses the database for querying or design work should know that there are views that can simplify their work.
One way to force users to use views is to restrict access to tables. This ensures that users use the views and not the tables and that there is no confusion about how to filter the data to get subsets of the tables.
In the case of the membership schema mentioned above, you can restrict access to the Memberships table and only provide access to the ApprovedMemberships and PendingMemberships views. This ensures that no one has to define what criteria to use to determine whether a membership is approved or pending.
It is also good practice to include the views in the database diagram and explain their usefulness with sticky notes. Any user looking at the diagram will also be aware of the existence of the views.
Naming convention criteria cannot be enforced by the database engine. This means that compliance must be overseen by a designer who controls the work of anyone who has permissions to create or modify the structure of a database. If no one is charged with overseeing naming convention adherence, it is of no use. While intelligent database design tools such as Vertabelo help ensure that certain naming criteria are met, full monitoring of the criteria requires a trained human eye.
On the other hand, the best way to enforce the criteria of a naming convention is for those criteria to be useful and practical. If they are not, users will comply with them reluctantly and drop them as soon as they can. If you have been given the task of defining a database schema naming convention, it is important that you create it with the purpose of benefiting the users. And make sure all users are clear about those benefits so they’ll comply with the convention without protest.
Subscribe to our newsletter Join our weekly newsletter to be notified about the latest posts. Subscribe